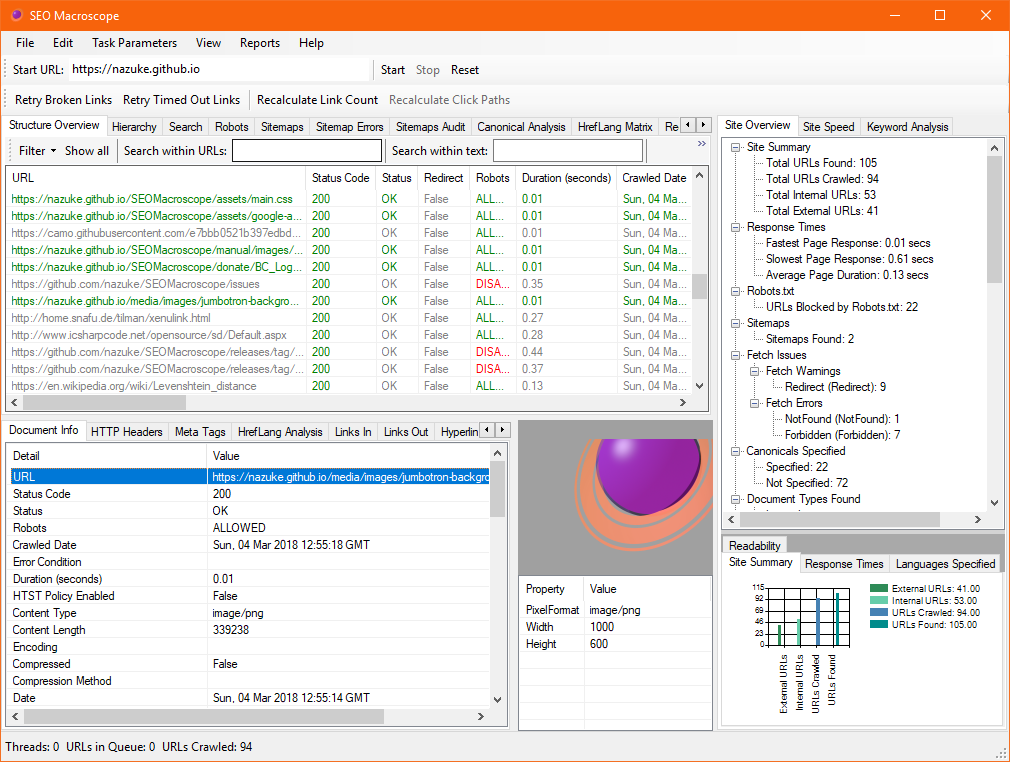
This release of SEO Macroscope includes support for HTTP/2 on Windows 10, and accelerates near-duplicate content detection. HTTP/2 support enables the application to work with websites that do not also support HTTP/1.1 as a fallback option.
As well as numerous bugs being fixed, the Levenshtein analysis of near-duplicate content has also been accelerated, by generating a “Levenshtein Fingerprint” of the document text of each web page as it is crawled. There are two analysis level options, with the second being slower but may help to eliminate false positives.
Where possible, the full text of PDF documents may be extracted, analyzed for readability, and URLs extracted. Currently, URLs found in the text will be added as additional outlinks from the PDF.
In some cases, QR Codes in linked image files on the site may be detected as containing a link. These can be further crawled.
In the source, I have also begun exploratory work on refactoring the core of SEO Macroscope into an “engine” library, with a view to building a CLI interface, and an updated WPF-based GUI. It would also be useful to be able to run multiple crawls concurrently, instead of only the currently supported single crawl.
Source code and an installer can be found on GitHub at:
Please check the downloads page for more recent versions.
I’ve also fixed many minor bugs and other issues.
New features in this release include:
- HTTP/2 support on Windows 10 machines.
- Improved crawl continuation when document type preferences have been changed.
- Optional detection of hyperlinks in QR Codes found in linked image files.
- Orphaned HTML pages may be reported. These are pages that are found via sitemaps, but may not be linked to from other HTML pages.
- More sitemap error reporting.
- More details in the Site Overview summary, such as number of document types found.
- Where possible, the text of PDFs is now fully extracted, and may be searched.
- Where possible, some URLs may be found in the text of PDFs, and further crawled.
- For text analysis, certain HTML5 navigational elements may now be disregarded.
- Some HTTP Status Codes, such as 410, may be ignored as errors.
- Redirect chains analysis
- Additional Excel and CSV reporting.
Bug fixes
There are too many fixes to list, but notable ones included:
- The “Maximum pages to fetch” setting has been reworked, and now works properly.
- Previously, outlinks for document types set as not crawlable were not being properly reported as outlinks in crawled documents; this has been corrected.
Please report issues at https://github.com/nazuke/SEOMacroscope/issues.