
Help Contents
- Getting Started
- File Menu
- Preferences Menu
- Spidering Control
- Analysis Options
- SEO Options
- Custom Filter Options
- Data Extractor Options
- Export Options
- Display Settings
- Network Settings
- Task Parameters Menu
- Presets
- View Menu
- Reports Menu
- URL Probing
- Crawled Results Lists
- Structure Overview
- Hierarchy
- Errors
- Search
- Robots
- Sitemaps
- Sitemap Errors
- Sitemaps Audit
- Canonical Analysis
- HrefLang Matrix
- Redirects Audit
- Redirect Chains
- Hostnames
- Links
- Hyperlinks
- URI Analysis
- Orphaned Pages
- Page Titles
- Descriptions
- Keywords
- Keywords Presence
- Page Headings
- Page Text
- Stylesheets
- Javascripts
- Images
- Audio
- Videos
- Email Addresses
- Telephone Numbers
- Custom Filters
- Data Extractors
- Remarks
- URL Queue
- History
- Document Detail Lists
- Crawl Overview Panels
- Excel and CSV Reports
- Concepts
Getting Started
To run a link scan of a website, simply enter a valid URL into the Start URL field, and click Start.
The running scan may be stopped at any time by clicking Stop. It may be resumed again by clicking Continue.
To clear the results of a full or partial scan, click Reset. Also, editing the Start URL will clear and reset the current scanned collection.
File Menu
Export sitemaps in text and XML formats, and list views to CSV and Excel files.
Recent URLs
This is a list of recently crawled URLs. Selecting one of them will put that URL back into the Start URL field, ready for crawling again.
Load Lists
A list of URLs to be scanned may be either loaded from a text file, or pasted from the clipboard. The scanning process is the same for either method.
Load and Save Sessions (Experimental)
This is an experimental feature, saved sessions may not be compatible with subsequent versions of SEO Macroscope.
The current session may be saved to a file, and then reloaded later. A crawl may be stopped, saved, reloaded, and then resumed.
This feature may be useful for saving the progress of very long crawls, or when it may be useful to examine a particular crawl at a later date.
Export Sitemaps
The crawled results may be exported to XML or Text format sitemap files.
Export Reports
The currently viewed list may be exported to CSV or Excel format files. This option is most useful for those list views that do not have their own report option, such as the search results list.
Preferences Menu
The default preferences are set to enable modest spidering of your site, but will omit attempting to download large files, will not descend into localized pages, and will not perform some of the more intense SEO analyses.
Some expensive processing options are also disabled by default, such as deep keyword analysis. Check these options, as some of them need to be enabled before crawling takes place.
Please refer to the preferences settings before beginning a spidering job.
Spidering Control
These settings control how SEO Macroscope crawls the links on your site.
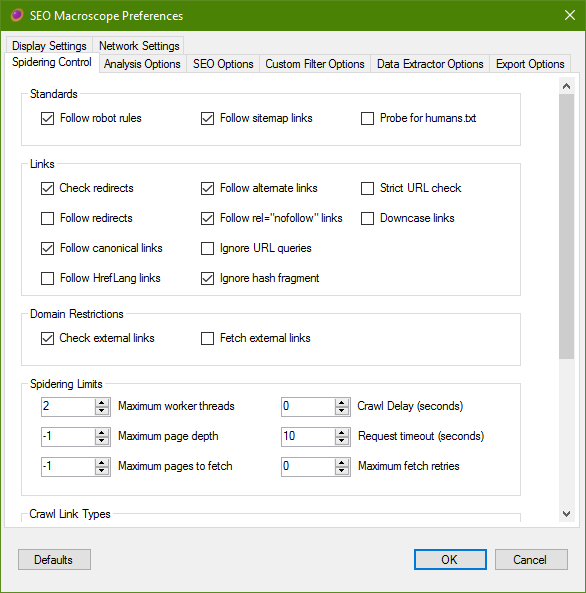
Standards
Follow Robot Rules (Partially implemented)
SEO Macroscope will honour the robots.txt directives, if present. Currently, this includes only those directives for the wildcard user agent.
As of this time, on-page robot directives are not implemented yet.
If present, the crawl delay directive in the robots.txt will be followed. Please note however that this delay is set per-thread. Which means that if crawling with 4 threads with a delay of 1 second, then your site may receive 4 requests per-second. Set the thread count low to begin with.
Also see Crawl Delay in the Spidering Limits section.
Follow Sitemap Links (Partially implemented)
SEO Macroscope will attempt to discover Google Sitemap XML files specified by your website, and follow the links in them.
The application will also use this setting to probe for well-known sitemap URLs.
For example:
https://www.company.com/sitemap.xml
Probe for humans.txt
If enabled, SEO Macroscope will attempt to fetch and process the humans.txt file on each crawled site.
For more information about humans.txt, please refer to:
http://humanstxt.org/
Links
Check redirects
If this option is checked, then SEO Macroscope will log and check redirects.
External URLs will only be logged.
Follow redirects
If this option is checked, then SEO Macroscope will log and follow redirects.
Redirected URLs will count as being internal hosts. Use caution here, as enabling this option may result in lengthy or infinite crawls.
In general, it is safer to crawl the sites redirected to separately.
External URLs will only be logged.
Follow canonical links
If this option is checked, then SEO Macroscope will log and follow canonical links, if present.
External URLs will only be logged.
Follow alternate links
If this option is checked, then SEO Macroscope will log and follow links element that have their rel attribute set as “alternate”.
External URLs will only be logged.
Follow rel=”nofollow” links
If this option is checked, then SEO Macroscope will log and follow HTML links that are set to “nofollow”, otherwise, those links will not be crawled.
Follow HrefLang links
If this option is checked, then SEO Macroscope will log and follow HrefLang links in the head section of HTML pages.
Please note that this will also mark localized hosts as being “internal” hosts.
Ignore URL queries
If this option is enabled, then the query string will be stripped from the URL, and the resultant bare URL crawled.
Ignore hash fragment
If this option is enabled, then the hash fragment will be stripped from the URL, and the resultant URL crawled.
In many cases, this may help to speed up crawling, as it will help to prevent duplicate content from being crawled.
Strict URL check
If this option is enabled, then strict include/exclude URL checking is applied before each URL is added to the crawl queue.
This may help to speed up the crawling process by eliminating some superfluous URLs from the crawl queue.
Downcase links
If this option is enabled, then the path component of all URLs added to the crawl queue will be downcased. Use this sparingly, as it may otherwise mask certain types of problems on the website.
Domain Restrictions
Check External Links
If this option is checked, then SEO Macroscope will log and follow links that are on external hosts.
Please note, this may result in an infinite crawl, or may otherwise take an extremely long time to complete.
Use the include/exclude Task Parameters to explicitly specify which external hosts you may potentially like to crawl.
Spidering Limits
These options control how aggressive SEO Macroscope is in its crawling.
Set low values to begin with.
Maximum Worker Threads
SEO Macroscope uses a threaded model to manage crawl workers.
To be conservative, set the number of threads to 1 initially.
Please note that the thread count combines with the Crawl Delay. The Crawl Delay applies to each thread, which means that your site may receive a request equal to the number of threads every Crawl Delay second(s).
Maximum Page Depth
Counting from the website’s document root of /, this is the maximum depth that SEO Macroscope will fetch a particular URL.
Maximum Pages To Fetch
This is approximately the maximum number of pages that SEO Macroscope will attempt to fetch.
It may fetch slightly more than this number.
Crawl Delay (seconds)
This overrides the Crawl Delay that may be set by the robots.txt directives for the website.
If set, then SEO Macroscope will pause after fetching each page in each thread for Crawl Delay second(s).
Request Timeout (seconds)
Set this to how long before SEO Macroscope should wait for a response from the server.
Maximum Fetch Retries
Set this to the number of attempts that SEO Macroscope should make when retrieving a page.
If you have a fast web server, then set this to a reasonably low value. Setting it too high may slow down the overall crawl if your web server is slow to respond.
Crawl Link Types
Please note that HTML documents are always crawled. Otherwise, to speed things up, we can exclude document types that we are not interested in crawling. In general, excluded document types may still have a HEAD request issued against them, but they will not be downloaded and crawled further.
CSS stylesheets
Enabling this option will cause CSS stylesheets to be fetched, and crawled.
Please not that currently, there is partial support for crawling further linked assets, such as background images, within stylesheets.
Javascripts
Enabling this option will cause Javascripts to be checked. Beyond that, no further crawling occurs with Javascripts.
Images
Enabling this option will cause images to be checked. Beyond that, no further crawling occurs with images.
Audio files
Enabling this option will cause audio files to be checked. Beyond that, no further crawling occurs with audio files.
Video files
Enabling this option will cause video files to be checked. Beyond that, no further crawling occurs with video files.
XML files
Enabling this option will cause XML files to be checked, and if applicable, crawled further.
This also includes Google Sitemap XML files. Disabling this option will cause those to not be downloaded and crawled.
Binary files
Binary files are any other file type for which no specific handling occurs.
For example, a linked .EXE file will have a HEAD request issued against it, to check that it is not a broken link.
URL List Processing
Scan sites in list
Enabling this option will cause SEO Macroscope to recurse into the websites for each URL in the URL list.
Please note that this may take a long time to complete if there are many websites included in the URL list.
Uncheck this option, if you only need to check the exact URLs in the URL list.
URL Probes
Probe parent folders
Enabling this option will probe parent directories for each URL found on an internal site.
This builds a new set of URLs to crawl, by taking the current URL, and progressively stripping off each rightmost element until it reaches the root.
Each stripped URL is then added to the list of URLs to crawl.
For example:
https://nazuke.github.io/SEOMacroscope/folder1/folder2/folder3/index.html
… will yield the following set of URLs to probe:
https://nazuke.github.io/SEOMacroscope/folder1/folder2/folder3/
https://nazuke.github.io/SEOMacroscope/folder1/folder2/
https://nazuke.github.io/SEOMacroscope/folder1/
https://nazuke.github.io/SEOMacroscope/
https://nazuke.github.io/
This may be used to probe for URLs on the site that are not otherwise linked to from elsewhere.
Analysis Options
Set further localization, list processing, and analysis options here.
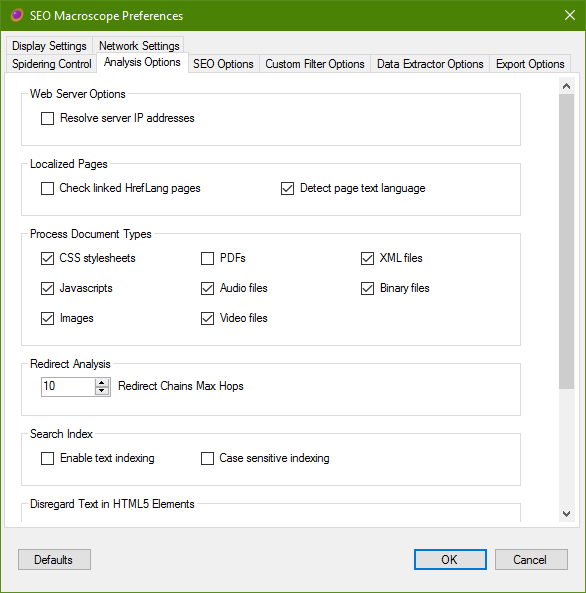
Web Server Options
Resolve server IP addresses
If checked, then the remote IP addresses for the host will be resolved and collected. Please note that each host may resolve to multiple IP addresses.
Localized Pages
Check linked HrefLang pages
Enabling this option will perform a simple HEAD request against detected HrefLang tags found in HTML pages.
By itself, this option will not cause SEO Macrosope to recurse into the websites referenced by the HrefLang tags if the referenced websites are considered to be “external.”
Enable the Follow HrefLang Links option under the Spidering Control tab if you would like to also scan the websites referenced by the HrefLang tags.
Detect page text language
If this option is enabled, then SEO Macroscope will attempt to detect the written language of the web page.
The results of this may be checked elsewhere. In some cases, this may flag mis-specified page language configuration, or translation problems.
Process Document Types
Please note that HTML documents are always crawled.
Otherwise, to speed things up, we can exclude document types that we are not interested in crawling or processing further.
CSS stylesheets
Enabling this option will cause CSS stylesheets to be parsed, with some links inside further crawled and processed.
Please not that currently, there is partial support for crawling further linked assets, such as background images, within stylesheets.
Javascripts
Enabling this option will cause Javascripts to be downloaded and analyzed.
Beyond that, no further crawling occurs with Javascripts.
Images
Enabling this option will cause images to be downloaded and analyzed.
Beyond that, no further crawling occurs with images.
PDFs
Enabling this option will cause PDF files to be downloaded, and if possible, processed and analyzed.
If this option is enabled, PDF texts will be processed in the same manner as HTML text, including having their keyword terms analyzed, and Levenshtein processing applied.
This option is off by default. Please note that enabling this option may consume a more bandwidth.
Audio files
Enabling this option will cause audio files to be downloaded and analyzed.
Beyond that, no further crawling occurs with audio files.
Video files
Enabling this option will cause video files to be downloaded and analyzed.
Beyond that, no further crawling occurs with video files.
XML files
Enabling this option will cause XML files to be downloaded, analyzed, and if applicable, crawled further.
This also includes Google Sitemap XML files. Disabling this option will cause those to not be downloaded and crawled.
Binary files
Binary files are any other file type for which no specific handling occurs.
For example, a linked .EXE file will have a HEAD request issued against it, to check that it is not a broken link, but disabling this option will not download the file itself.
Redirects
Redirect Chains Maximum Hops
Set this value to the maximum acceptable number of redirects to be displayed in a chain in the Redirect Chains list.
Search Index
Enable text indexing
If enabled, then text content in HTML pages will be indexed and searchable after a crawl.
Case sensitive indexing
If enabled, then text content will indexed and searchable in a case sensitive manner.
Page Fault Analysis
Warn about insecure links
Enabling this option will report insecure links to pages or resources from secure pages.
SEO Options
Configure SEO policies and analysis options here. SEO guidelines can change over time, so it is possible to set the ideal desired thresholds for certain page attributes as you see fit.
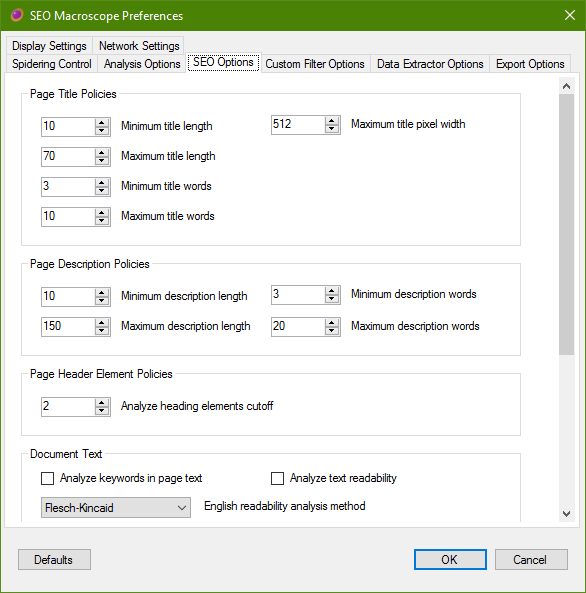
Page Title Policies
Minimum title lenth
Set this to the minimum number acceptable characters, including white space, for page titles.
Maximum title lenth
Set this to the maximum number acceptable characters, including white space, for page titles.
Minimum title words
Set this to the minimum number acceptable number of words for page titles.
Maximum title words
Set this to the maximum number acceptable number of words for page titles.
Maximum title pixel width
Set this to the maximum acceptable width in pixels of the page title.
This value is calculated approximately.
Page Description Policies
Minimum description lenth
Set this to the minimum number acceptable characters, including white space, for page descriptions.
Maximum description lenth
Set this to the maximum number acceptable characters, including white space, for page descriptions.
Minimum description words
Set this to the minimum number acceptable number of words for page descriptions.
Maximum description words
Set this to the maximum number acceptable number of words for page descriptions.
Page Header Element Policies
Analyze heading elements cutoff
Set this option to the maximum page header level that you are interested in analyzing.
Document Text
Analyze keywords in page text
If this option is enabled, then some analysis is performed on keywords in the page body text.
Please note, this process occurs at the end of a scan, and may take quite some time to complete.
Analyze text readability
If this options is enabled, then the readability algorithm specified is appled to the document body text, dependent upon the document language.
English readability analysis method
Select the readability analysis algorithm for the English language.
Levenshtein Edit Distance Processing
In addition to other methods, I have implemented a Levenshtein Edit Distance approach for attempting to detect near-duplicate content.
What this means is that for each HTML or PDF document that is fetched, the human-readable text is extracted and cleaned into a sanitized format.
By then applying the Levenshtein algorithm, we can discover pages that have text content that is similar to each other, within a certain threshold.
Please note that applying this method may incur a significant overhead, especially on larger crawls.
Enable Levenshtein Duplicate Detection
Enabling this option will make the Levenshtein Edit Distance algorithm be applied in some areas of the application.
Currently, the comparison data is only available in the duplicate content Excel report.
Levenshtein Analysis Level
The Levenshtein analysis can be quite expensive computationally, so there are two analysis levels that may be chosen to assist with speeding up the process.
When the text of each web page is extracted, SEO Macroscope generates a “Levenshtein Fingerprint” of the text. This is a vastly simplified representation of the text in the document, and may more quickly be analyzed.
-
Level 1 will use only the Levenshtein Fingerprint for analysis of the document set. Generally, this will be sufficient to identify most near-duplicates in a reasonable time. This may yield false-positives.
-
Level 2 will execute the Level 1 pass, but then apply the Levenshtein algorithm on the full text of documents that are identified as being near-duplicates.
Maximum Levenshtein Text Length Difference
This value is used to consider whether to apply the Levenshtein algorithm to two documents, or not.
The value is the difference in byte-lengths between the two texts of the two documents.
If the two documents are within this threshold, then the Levenshtein algorithm is applied, if not, then they are considered to be too different.
Levenshtein Edit Distance Threshold
Set this value to the maximum number of “edits” that consider the two documents to have very similar texts.
Custom Filter Options
The custom filters may be used to check that your website pages contain, or do not contain, a specific value.
Enable/Disable Custom Filters
Enable custom filter processing
Enable this option to activate the custom filter processing during a crawl. Disabling this option may speed up a crawl slightly.
Custom Filter Items
Number of custom filters
Set this option to the exact number of custom filters needed for the crawl.
Apply Custom Filters to Document Types
Check only those document types that need to have custom filters applied to them. Unchecking unneeded document types may help to speed up the crawling process.
Data Extractor Options
Content may be scraped from the crawled pages by using regular expressions, XPath queries, or CSS selectors.
Enable/Disable Data Extractors
Enable data extraction processing
Enable this option to activate the data extraction processing during a crawl. Disabling this option may speed up a crawl slightly.
Extractor Items
Number of CSS Selectors extractors
Set this option to the exact number of CSS Selectors extractors needed for the crawl.
Number of Regular Expression extractors
Set this option to the exact number of Regular Expression extractors needed for the crawl.
Number of XPath Expression extractors
Set this option to the exact number of XPath Expression extractors needed for the crawl.
Apply Data Extractors to Document Types
Check only those document types that need to have data extractors applied to them. Unchecking unneeded document types may help to speed up the crawling process.
Process Text
Clean white space
Enable this option to clean white space in extracted data. Each item will be topped and tailed, and have internal white space compacted.
Export Options
These settings control how SEO Macroscope exports your crawled data.
Sitemaps
Specify additional options during sitemap generation.
Include linked PDFs
This takes effect when exporting XML and text sitemaps.
Enabling this option will cause links to PDFs from HTML pages to be included in the export sitemap, even if the PDF URL would normally be excluded from this crawl session.
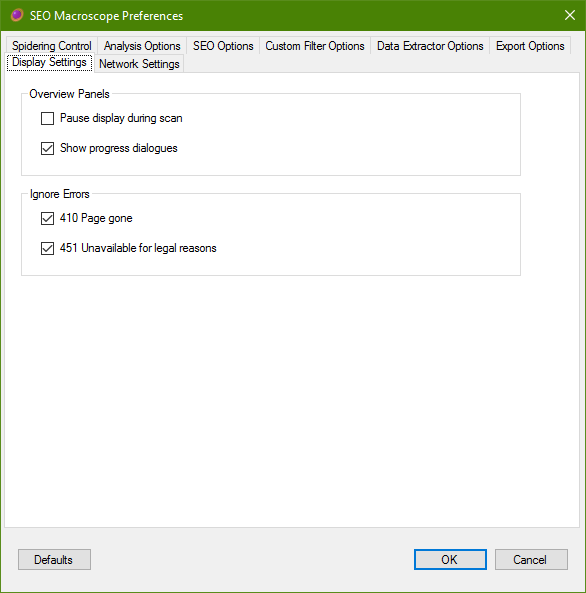
Display Settings
These settings control how SEO Macroscope updates the display during a crawling operation.
Overview Panels
Pause display during scan
Disabling this option will prevent the various list displays from being updated during crawling. This is mostly a cosmetic effect, but may reduce time it takes to complete the crawl slightly.
Show progress dialogues
Disabling this option will prevent progress dialogues from being displayed.
Network Settings
Configure your network settings here.
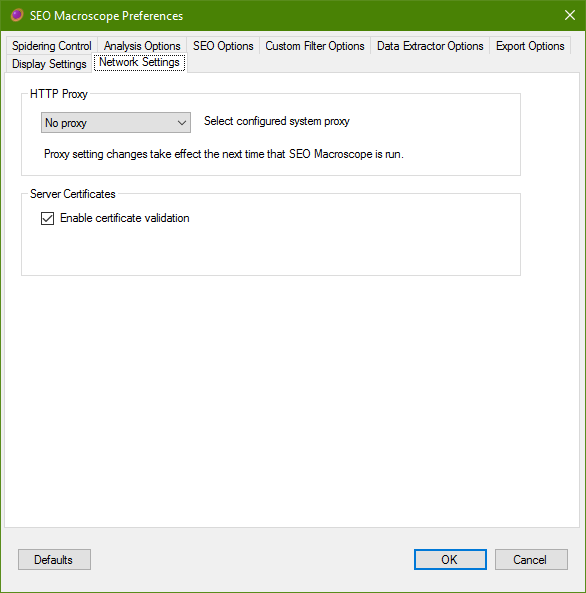
HTTP Proxy
Configure your web proxy settings here. Please consult your network administrator, if necessary.
Select configured system proxy
- Select No proxy to disable the use of a web proxy.
- Select WinInetProxy to use the web proxy configured in your Internet Explorer or Edge preferences. In many cases, this is the most commonly required option.
- Select WinHttpProxy to use the system-wide web proxy configured for your system.
Server Certificates
Enable certificate validation
Disabled this option to skip server certificate validation checks.
WARNING: Do not disable this unless you are sure that you know what you are doing.
This option is most useful for working with development sites that use self-signed certificates.
Task Parameters Menu
Set crawl-specific parameters.
Include URL Patterns
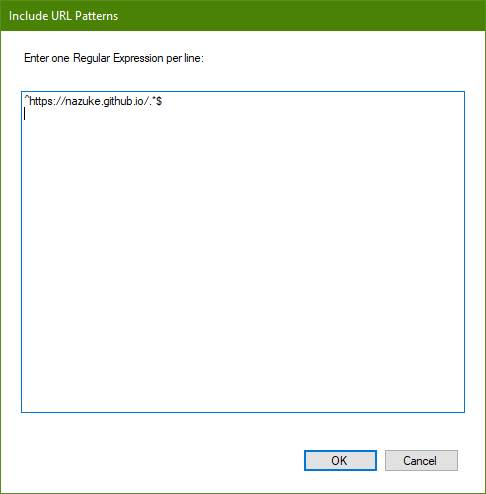
Enter one or more regular expressions that each crawled URL must match in order to be considered for crawling.
Exclude URL Patterns
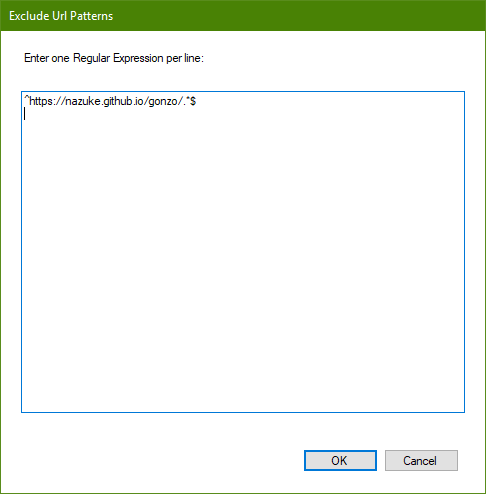
Enter one or more regular expressions that each crawled URL must not match in order to be considered for crawling.
Custom Filters
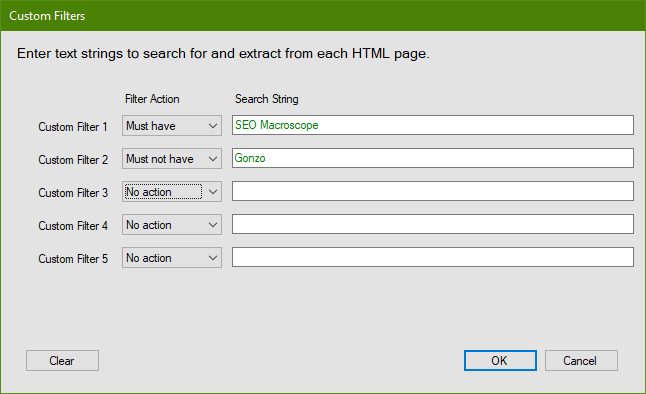
Each custom filter may be entered as either plain text, or a regular expression.
Data Extractors
Content may be scraped from the crawled pages by using regular expressions, XPath queries, or CSS selectors.
The scraped data may then be exported to CSV or Excel format report files.
CSS Selectors
Web scraping may be done with CSS selectors.
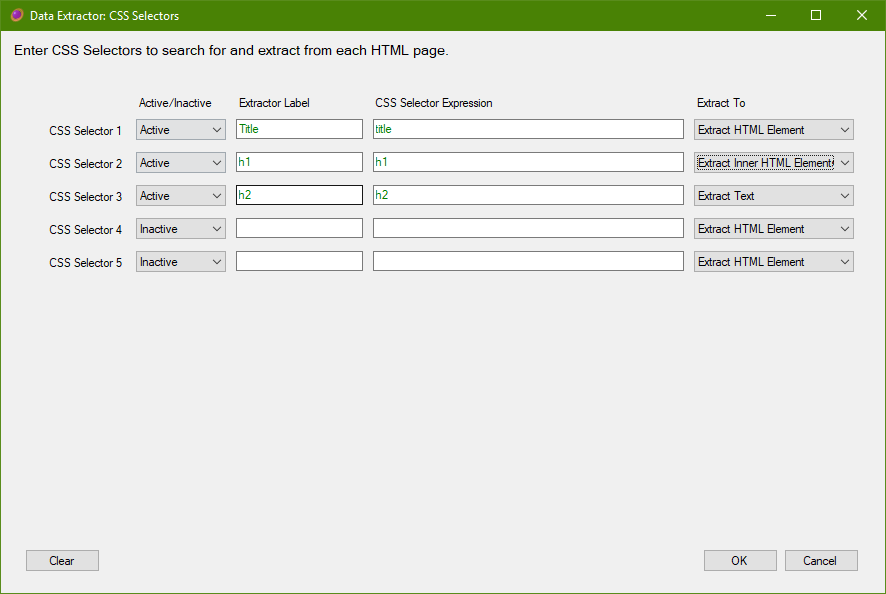
Give each extractor a name, this will be used in the list views, and CSV/Excel reports, for each found item.
Enter a CSS selector query that will locate the data that you wish to extract.
Finally, specify whether the CSS selector should extract the matched HTML element and all of its children, only the matched child elements, or extract only the text value.
Regular Expressions
Web scraping may be done with regular expressions.
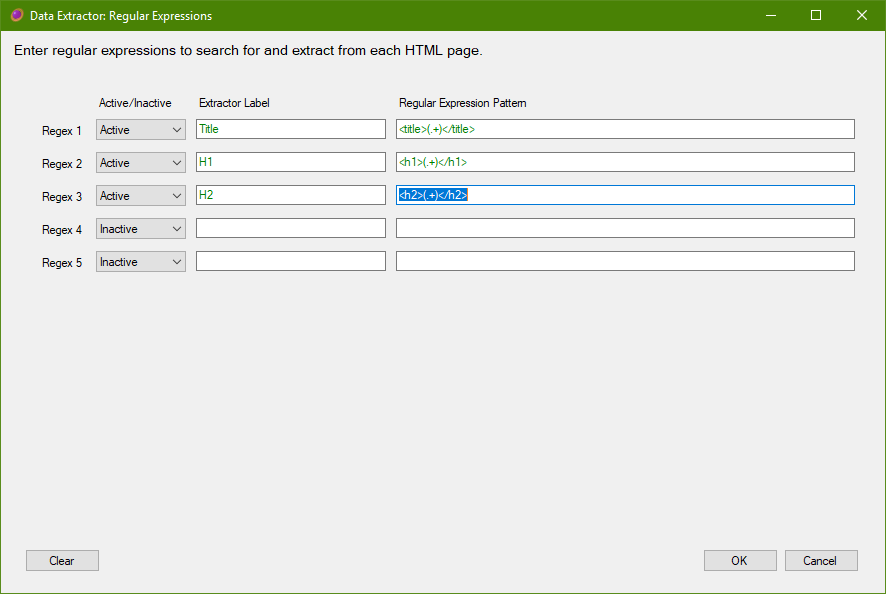
Give each extractor a name, this will be used in the list views, and CSV/Excel reports, for each found item.
Enter a regular expression that will locate the data that you wish to extract.
It is important that the regular expression includes capture groups; otherwise nothing will be extracted. Each capture group will be extracted into its own record.
XPath Queries
Web scraping may be done with XPath queries.
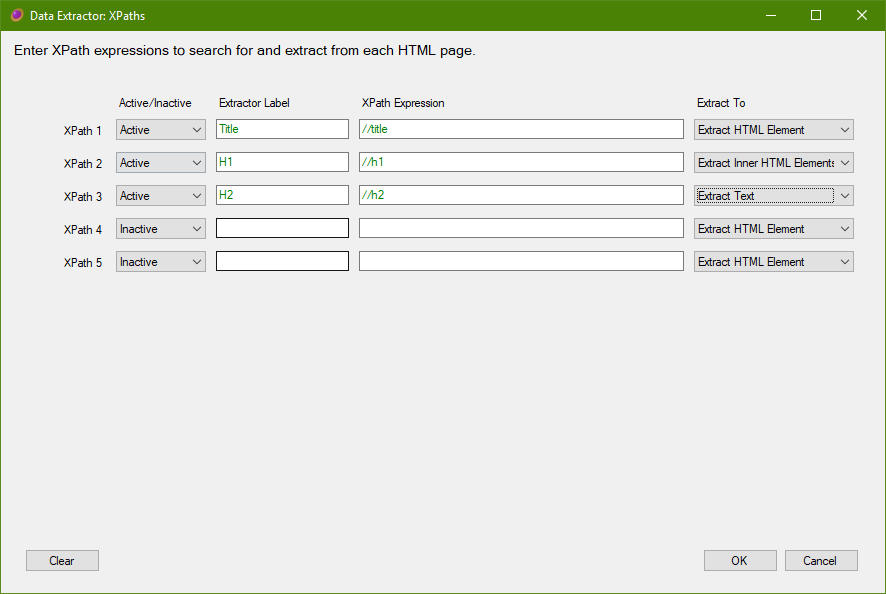
Give each extractor a name, this will be used in the list views, and CSV/Excel reports, for each found item.
Enter a XPath query that will locate the data that you wish to extract.
Finally, specify whether the XPath query should extract the matched HTML element and all of its children, only the matched child elements, or extract only the text value.
Clear HTTP Authentication
This will clear any previously entered usernames and passwords entered during this crawl session.
Please Note: usernames and passwords are not cached, or saved on application exit, they will need to be entered each time a new crawl is made.
Presets
Use these commands to quickly recall predefined crawl configuration settings.
Please note that choosing a preset will first set the crawl settings to the defaults, so if you want to crawl only HTML pages, but also include linked images, then choose HTML Only first, and then go into the preferences panel and add the images options.
Further presets for common types of crawl tasks may be added in future.
HTML Only
This preset will crawl only the web pages of the website, all linked assets and other document types will be ignored.
HTML and PDFs
This preset does the same as HTML Only, but will also crawl PDF files.
HTML and Linked Assets
This preset does the same as HTML Only, but will also crawl linked CSS, JS, images, videos, etc.
HrefLang Matrix
This preset does the same as HTML Only, but will also crawl pages referenced in HrefLang tags.
Default Settings
This does the same thing as pressing the Default button in the preference window. It will reset all settings to the defaults.
View Menu
Quickly switch between lists from the View menu.
Reports Menu
Export reports to Excel or CSV format files.
Also refer to the File->Export commands.
Excel Reports
Reports may be exported to Excel format for most types of lists.
The Excel reports each combine one or more worksheets into a single report file.
CSV Reports
Reports may be exported to CSV format for most types of lists.
Each worksheet must be exported to a separate CSV file.
URL Probing
Some URLs may be automatically probed for, even if they are not referenced from anywhere else on the site.
For example:
/robots.txt
/humans.txt
/favicon.ico
/sitemap.xml
Crawled Results Lists
The crawled results lists are the upper tabbed panels on the left hand side of the SEO Macroscope window.
These lists reveal various aspects about the pages and documents found during a crawl.
In many of these list views, clicking the row will show the details of the URL selected in the lower panel.
Structure Overview
This tab shows a general overview of all URLs found during the crawl.
Hierarchy
This tab shows a tree view of the crawled URLs, it displays an outline of the crawled sites.
Errors
This tab displays the critical errors found during the crawl.
Search
TBD
Robots
This tab displays URLs that were blocked according to the rules found in the site’s robots.txt file.
Sitemaps
This tab displays the XML sitemaps discovered during the crawl.
Sitemap Errors
This tab displays the errors found in the XML sitemaps during the crawl.
Sitemaps Audit
This tab shows how the robot rules were applied to URLs in the XML sitemaps during the crawl.
Canonical Analysis
TBD
HrefLang Matrix
TBD
Redirects Audit
TBD
Redirect Chains
TBD
Hostnames
TBD
Links
TBD
Hyperlinks
TBD
URI Analysis
TBD
Orphaned Pages
TBD
Page Titles
TBD
Descriptions
TBD
Keywords
TBD
Keywords Presence
TBD
Page Headings
TBD
Page Text
TBD
Stylesheets
TBD
Javascripts
TBD
Images
TBD
Audio
TBD
Videos
TBD
Email Addresses
TBD
Telephone Numbers
TBD
Custom Filters
TBD
Data Extractors
This lists scraped data as specified under *Task Parameters -> Data Extractors.
CSS Selectors
TBD
Regular Expressions
TBD
XPaths
TBD
Remarks
TBD
URL Queue
TBD
History
TBD
Document Detail Lists
The document detail lists are the lower tabbed panels on the left hand side of the SEO Macroscope window.
These lists reveal various aspects about specific the specific document selected in one of the crawled results list panels. Only those crawled results list panels that have a URL column will activate the document detail panel.
TBD
Crawl Overview Panels
These are the panels on the upper right hand side. These display various aspects and statistics about the entire crawled collection.
Site Overview
TBD
Site Speed
TBD
Keyword Analysis
TBD
Excel and CSV Reports
TBD
Concepts
Explanations of how SEO Macroscope deals with a few details under the hood.
“Internal” and “External” Hosts
Briefly, SEO Macroscope maintains the notion of a URL as belonging to either an “internal”, or an “external” host.
- Internal hosts will generally be crawled, dependent on other preference settings; whereas external hosts will not. In many places, URLs are highlighted as green when they are considered internal.
- An “internal” host is one that is explicitly specified either via the Start URL field, or is present in a loaded or pasted URL list. There is also the option of using the context menu in some of the overview panels, to mark a particular URL as belonging to an internal host.
- An “external” host is generally one that is linked to from HTML pages or stylesheets, but is different to the Start URL or URL list host(s).
Generally, external hosts will be issued a HEAD request, but will not be crawled.
Links vs Hyperlinks
SEO Macroscope differentiates “Links” and “Hyperlinks” like so:
- Links in a crawled document include all HTML element types, and some other document type links, that form a link to/from the current document, and some external crawlable resource. The list of links are what SEO Macroscope extracts from a document, and considers for crawling. For example, an HTML document would include links to the following external resources:
- CSS files
- Javascripts
- Images
- Other web pages
- PDFs
- Etc…
- Hyperlinks in a crawled document are all of the links that could be clicked on by a user in a web browser, including Hyperlinks from other pages in the crawled collection.
Generally, webmasters will be interested in looking at problems with Links; where SEO people will likely want to be examining the Hyperlinks.